Google Announces New Location for Crawlers’ IP Range Files
Google has announced an important infrastructure update affecting how developers and systems access crawler IP range data. The update was officially published on the Google Search Central Blog on March 31, 2026.
This change does not impact rankings directly, but it plays a critical role in how servers verify Googlebot and other Google crawlers. For developers, SEOs, and system administrators, this is a practical update that requires attention, especially for those managing firewalls, bot validation systems, or crawl monitoring tools. (Source)
What Google Actually Changed
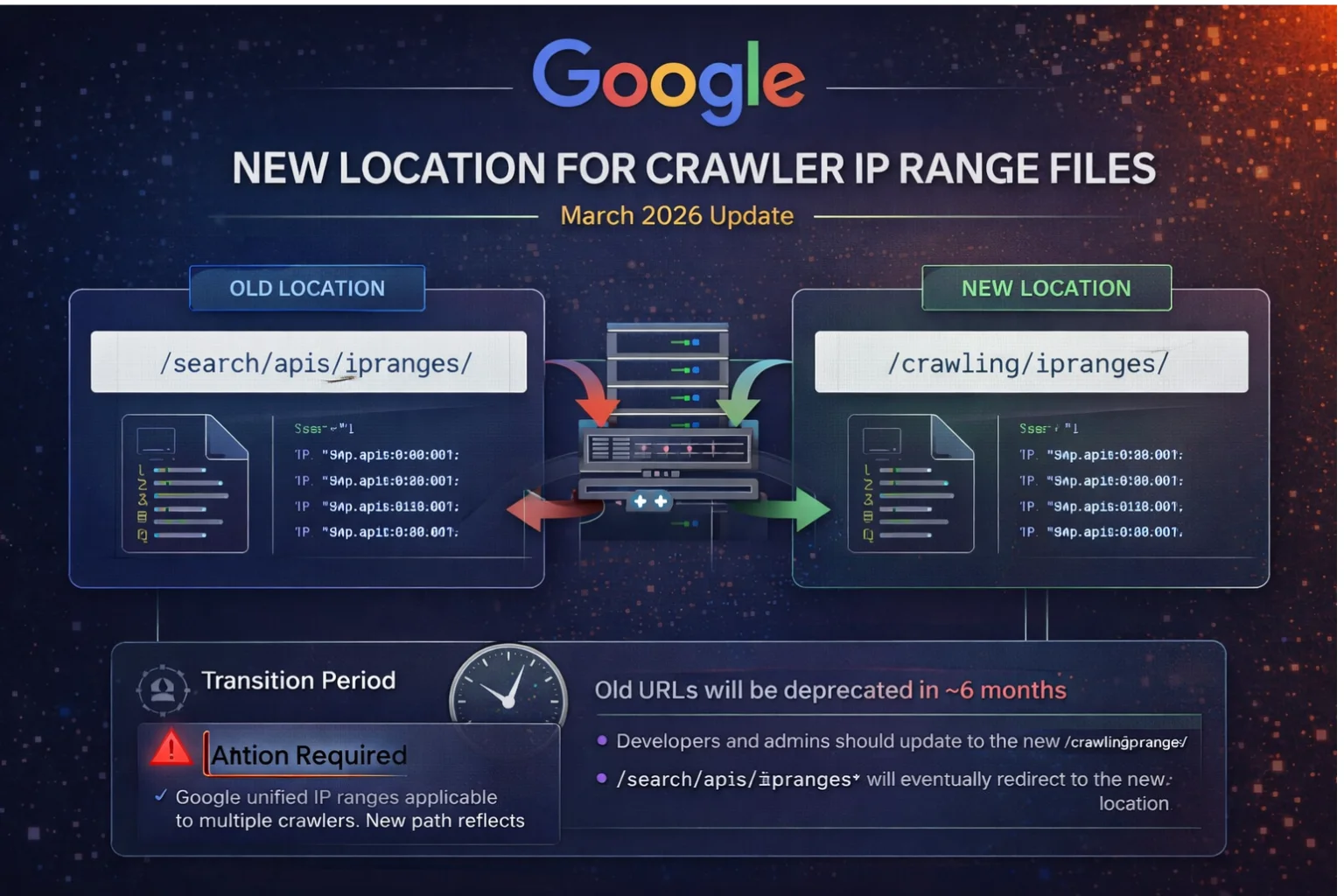
Google has moved the location of its crawler IP range JSON files to a new directory.
Previously, these files were hosted under a path associated with Search APIs. Now, they are being relocated to a broader crawling-related directory. The reason behind this change is simple but important: these IP ranges are not limited to Google Search alone.
They are used by multiple Google services that rely on the same underlying crawling infrastructure. By moving them to a centralized location, Google is making the structure more accurate and scalable.
Why This Update Matters
At first glance, this might look like a small documentation change, but in practice, it has real implications.
Many systems rely on Google’s IP range files to:
- Verify whether traffic is coming from Google
- Allow or block access at the server level
- Configure security rules and bot filtering
If a system continues using outdated endpoints after deprecation, it may fail to validate Google crawlers correctly. This can lead to accidental blocking of legitimate Googlebot traffic or incorrect identification of bots.
How the Transition Is Being Handled
Google is not forcing an immediate switch. Instead, it is providing a transition window.
Both the old and new locations are currently active. This allows developers time to update their systems without breaking functionality. However, Google has clearly stated that the old paths will eventually be phased out and redirected to the new ones.
The expected transition period is up to six months. After that, reliance on old URLs will no longer be reliable.
What Developers Should Do Now
This update requires a proactive approach. Waiting until deprecation can cause avoidable issues.
First, systems that fetch or rely on crawler IP ranges should be reviewed. Any reference to the old path should be identified and replaced with the new location.
Second, firewall and security configurations should be updated. Many servers whitelist Google IP ranges, and these systems must point to the correct source.
Finally, it’s important to monitor logs and behavior during the transition. This ensures that updates have been applied correctly and that Googlebot is still being recognized properly.
Real-World Impact Scenario
Consider a website that uses automated scripts to fetch Google IP ranges daily.
If the script continues using the old endpoint after it is deprecated, the system may fail to retrieve updated data. Over time, this can result in outdated IP lists.
This creates two risks:
- Real Google crawlers may get blocked
- Fake bots may bypass verification
By updating early, this risk is completely avoided.
Relationship With Google’s Crawling System
This update also connects with Google’s broader explanation of its crawling infrastructure.
As Google has clarified, its crawling system is centralized and used by multiple services. This reinforces why a general “crawling” directory makes more sense than a “search-only” path.
It reflects how Google’s systems are structured internally and ensures consistency across documentation and implementation.
What This Update Does NOT Change
It is equally important to understand what this update does not do.
This change:
- Does not affect rankings
- Does not change crawling behavior
- Does not modify how Googlebot interacts with websites
It is purely an infrastructure and documentation update.
However, incorrect implementation on your side can still indirectly affect crawling if Googlebot gets blocked.
Long-Term Implications
This update signals a continued effort by Google to standardize and centralize its developer-facing resources.
For website owners and developers, the message is clear: systems should not rely on static or outdated endpoints. Instead, they should stay aligned with Google’s official documentation and updates.
Technical SEO is increasingly about maintaining correct infrastructure, not just optimizing content.
FAQ
Google moved the files because the IP ranges are not limited to Google Search. They are used by multiple Google services that rely on the same crawling infrastructure. The new location reflects this broader usage and provides a more logical structure.
Google has not made it mandatory immediately, but it strongly recommends updating as soon as possible. Since the old URLs will be phased out within approximately six months, delaying the update can lead to system failures later.
Initially, nothing will break because Google is maintaining backward compatibility during the transition. However, once the old URLs are deprecated and redirected, systems depending on them may stop working properly or fetch incorrect data.
No, this update does not directly affect rankings or SEO performance. It is purely a technical infrastructure change. However, incorrect IP validation could indirectly impact crawling if Googlebot is blocked by mistake.
You should audit your code, scripts, firewall rules, and any automation that relies on Google IP ranges. Replace old endpoints with the new /crawling/ipranges/ path and monitor server logs to confirm that Googlebot traffic is being handled correctly.
Author
Harshit Kumar is an AI SEO Specialist with 7+ years of experience and the founder of kumarharshit.in. He is known for technical SEO insights, indexing systems, and breaking down Google updates into actionable strategies.


Leave a Reply